

AWS Serverless Project: Praful's resume pdf download serverless Web Application
PRAFUL PATEL ☁️🚀, Highly skilled and motivated Cloud Engineer with a proven track record of designing, implementing, and managing robust cloud infrastructure solutions. With years of hands-on experience, I am deeply passionate about creating scalable and resilient cloud architectures that drive innovation and deliver optimal business outcomes. 🛠 Key Competencies:
Cloud Platforms: AWS, Azure, GCP, OCI Infrastructure as Code: Terraform, Ansible Containers & Orchestration: Docker, Kubernetes Scripting: Python, Bash/Shell CI/CD & Version Control: GitHub, Jenkins, CircleCI Monitoring & Analytics: Grafana, Prometheus, Datadog, New Relic Backup & Recovery: Veeam Operating Systems: Linux, Windows DevOps Tools: AWS Code Build, Code Pipeline, Azure DevOps
📚 Continuous Learning: Staying ahead in the rapidly evolving cloud landscape is my priority. I am committed to expanding my skill set and embracing emerging cloud technologies to drive efficiency and innovation. Passionate Cloud/DevOps enthusiast dedicated to designing, building, and deploying cutting-edge technology solutions. As a devoted YouTuber, I love sharing insights through informative videos and crafting technical blogs that delve into areas like ☁️ Cloud, 🛠️ DevOps, 🐧 Linux, and 📦 Containers. 💻 Open Source Advocate: Contributing to open-source projects is a vital part of my journey. I actively engage in projects centered around Cloud, DevOps, Linux, and Containers, fostering collaboration and innovation within the community. 💌 Let's Connect: I am enthusiastic about virtual collaborations and meeting fellow professionals. Let's explore how I can contribute to your organization's cloud goals. Feel free to connect or DM me.
🌐 Portfolio: Check out my portfolio 🔗 LinkedIn: Connect on LinkedIn 🛠️ GitHub: Explore my projects 🎥 YouTube: Watch my videos 📝 Medium: Read my articles 🌐 Dev.to: Check out my posts
This project leverages AWS serverless services to provide resume download functionality and a visitor counter for a portfolio website. The frontend includes various JavaScript libraries for animations and interactive components, while the backend uses AWS Lambda and DynamoDB to deliver dynamic functionalities.
GitHub Repo: https://github.com/prafulpatel16/prafuls-portfolio-webapp
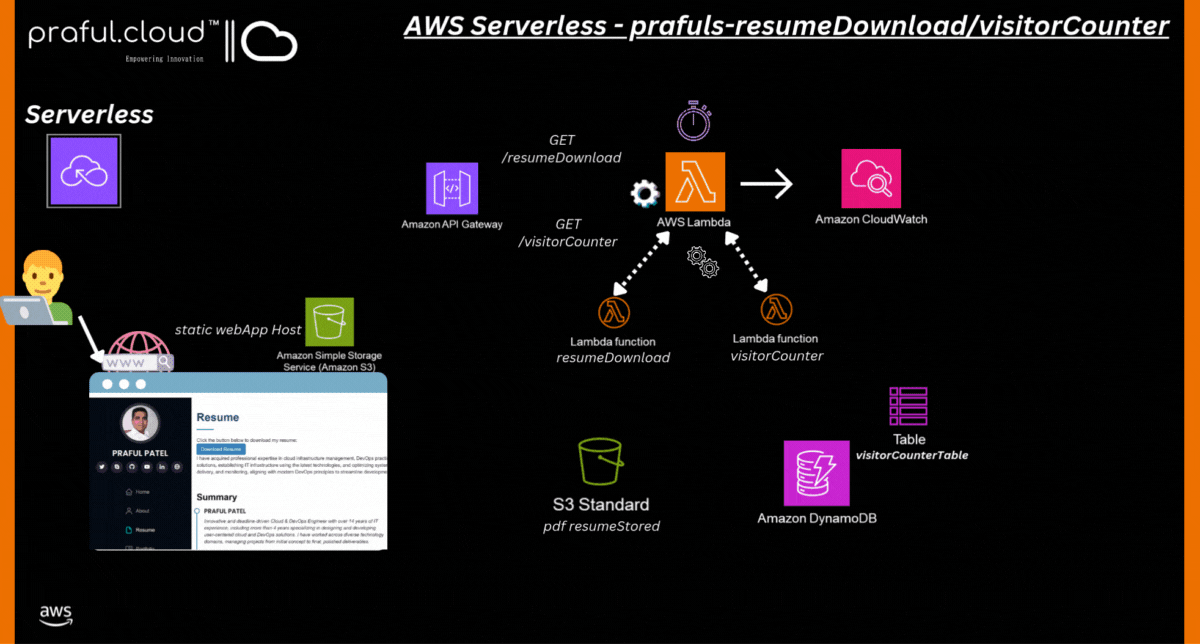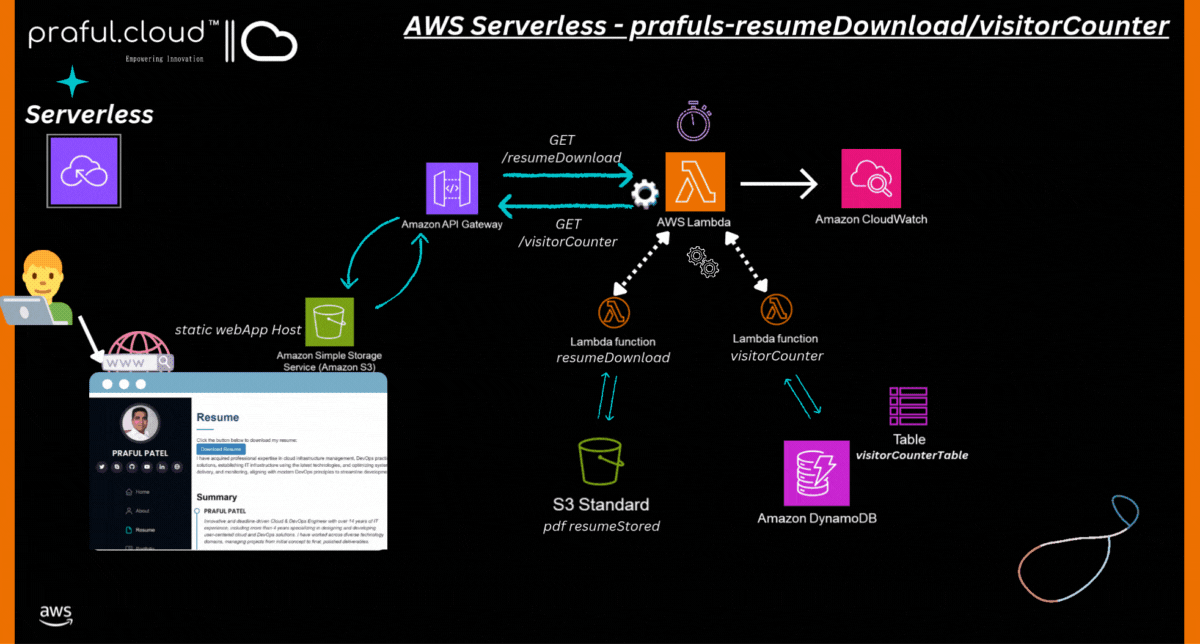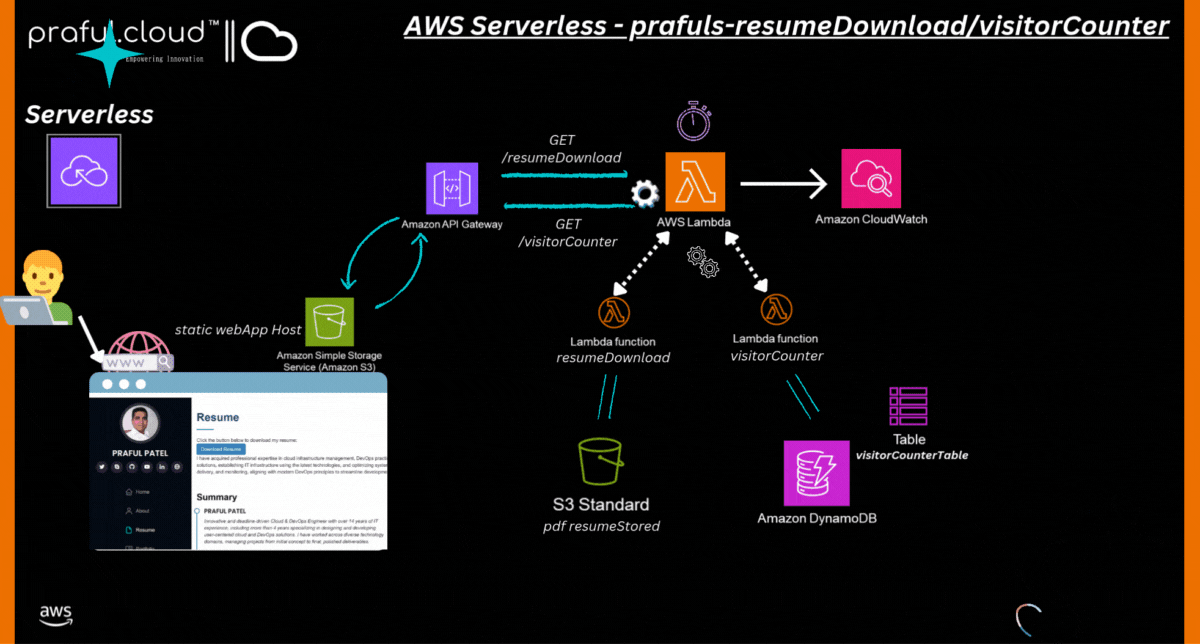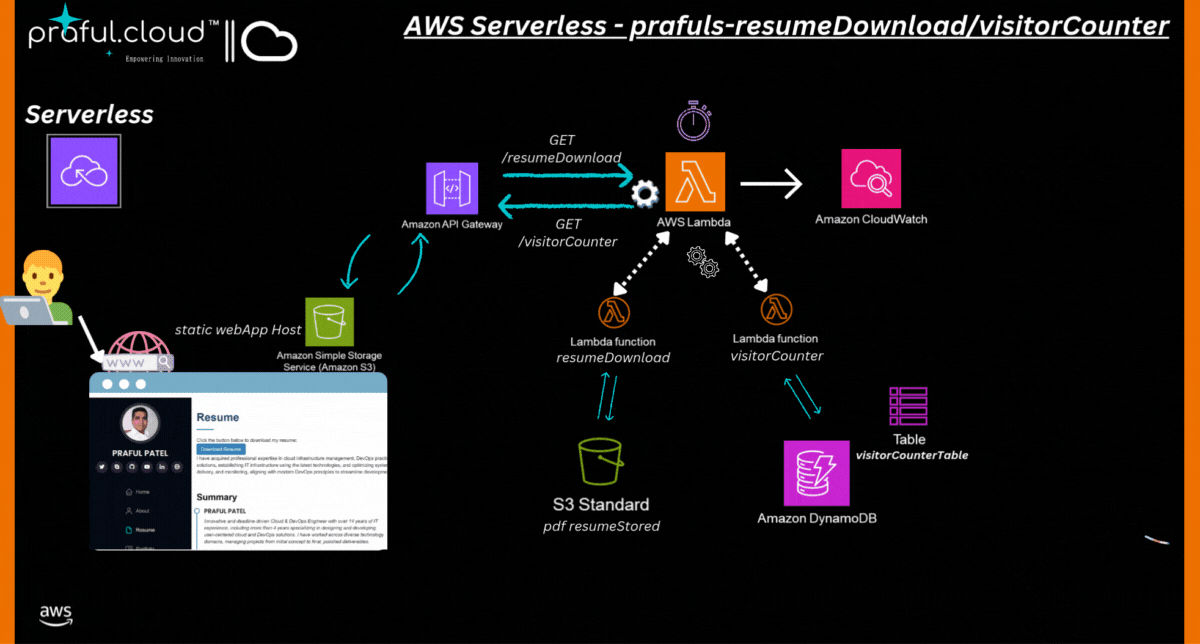
Solution Diagram: AWS Serverless Architecture

Frontend:
HTML/CSS/JavaScript: For building the website structure and interactivity.
Bootstrap: For responsive design and styling.
Google Fonts: For custom fonts.
JavaScript Libraries:
Typed.js: For typing animation on the website.
PureCounter.js: For dynamic visitor counter on the frontend.
AOS.js: For animations on scroll.
Swiper.js: For testimonial slider functionality.
Backend:
AWS Lambda: For serverless functions that handle resume downloads and visitor counting.
AWS API Gateway: For exposing API endpoints for the Lambda functions.
AWS DynamoDB: For storing visitor counts and incrementing them for each visit.
AWS S3: For storing the resume PDF file that users can download.
Cloud Infrastructure & Security:
AWS IAM: For managing roles and policies to secure Lambda access to S3 and DynamoDB.
AWS CloudWatch: For logging and monitoring Lambda functions.
AWS WAF (optional): For protecting the API Gateway endpoints (not implemented but recommended).
Version Control & Project Management:
Git: For version control.
GitHub: For hosting and collaboration on the project.
Scripting:
Python: Used in Lambda functions to handle resume downloads and visitor counter logic.
Boto3: Python SDK to interact with AWS services (S3, DynamoDB, etc.).
Deployment & Hosting:
- AWS Free Tier: Keeping costs within the AWS Free Tier by leveraging free-tier limits on Lambda, API Gateway, S3, and DynamoDB.
Table of Contents
Introduction
Project Structure
System Design Overview
Infrastructure Setup
IAM Role Setup
Lambda Function Setup
API Gateway Setup
Resume Download Functionality
Implementation Overview
S3 Configuration
API Gateway-Lambda Integration for Resume Download
Visitor Counter Functionality
Implementation Overview
DynamoDB Configuration
API Gateway-Lambda Integration for Visitor Counter
Security Measures
Budget Considerations
Deployment Diagram
Final Testing & Validation
1. Introduction
This project demonstrates how to build a serverless web application with a Resume Download Functionality and Visitor Counter using AWS services. The primary focus is on leveraging API Gateway, Lambda Functions, S3, DynamoDB, and IAM roles. This system ensures that the infrastructure operates efficiently within the AWS Free Tier limits and maintains a budget of $10/month for all AWS resources.
2. Project Structure
bashCopy code/project-root
├── /forms
│ └── insert.php (for contact form)
├── /assets
│ ├── /css (for stylesheets)
│ ├── /img (for images, including the resume)
│ └── /js (for JavaScript)
├── index.php (Main Website)
└── README.md (Project Documentation)
3. System Design Overview
System Architecture
The architecture consists of:
Frontend: A simple HTML/Bootstrap-based web page hosted via a static site generator (e.g., AWS S3 or EC2).
Backend Services: Lambda functions that handle:
Resume Download: Fetching the resume from an S3 bucket and allowing the user to download it.
Visitor Counter: Logging visits in a DynamoDB table and returning the visitor count.
Core AWS Services Used:
S3: Stores the resume PDF.
Lambda: Handles the backend logic (fetching the resume and tracking visitor count).
API Gateway: Exposes API endpoints for Lambda functions.
DynamoDB: Stores visitor count.
IAM Roles: Manages access permissions.
4. Infrastructure Setup
4.1 IAM Role Setup
Steps:
Create IAM Role for Lambda Execution:
Go to IAM in the AWS console.
Click on "Roles" > "Create Role."
Choose "Lambda" as the trusted entity.
Attach the following policies:
AmazonS3ReadOnlyAccess: Allows Lambda to read from the S3 bucket.AmazonDynamoDBFullAccess: Allows Lambda to interact with DynamoDB.AWSLambdaBasicExecutionRole: Grants Lambda access to CloudWatch for logs.
Give the role a meaningful name (e.g.,
Lambda-Resume-Download-Role).

Policy for S3 Access: Ensure the following policy is attached:
code{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": "s3:GetObject", "Resource": "arn:aws:s3:::your-bucket-name/*" } ] }

4.2 Lambda Function Setup
Steps to Create Lambda Function for Resume Download:
Create Lambda Function:
Go to AWS Lambda and click "Create Function."
Choose the "Author from scratch" option.
Name the function
ResumeDownloadFunction.Choose the runtime (Python 3.9 or Node.js as per your choice).
Set the IAM role to the one you created (
Lambda-Resume-Download-Role).
Lambda Code:
import json import boto3 import base64 import os from botocore.exceptions import ClientError s3 = boto3.client('s3') def lambda_handler(event, context): bucket_name = os.getenv('S3_BUCKET_NAME') resume_key = os.getenv('RESUME_KEY') try: # Fetch the resume PDF from S3 response = s3.get_object(Bucket=bucket_name, Key=resume_key) pdf_content = response['Body'].read() # Return the PDF file as binary stream return { 'statusCode': 200, 'headers': { 'Content-Type': 'application/pdf', 'Content-Disposition': 'attachment; filename="Praful_Resume.pdf"', }, 'body': base64.b64encode(pdf_content).decode('utf-8'), 'isBase64Encoded': True # This must be True for binary files } except ClientError as e: error_code = e.response['Error']['Code'] return { 'statusCode': 500, 'body': json.dumps(f"Error downloading resume: {error_code} - {str(e)}") } except Exception as e: return { 'statusCode': 500, 'body': json.dumps(f"Error downloading resume: {str(e)}") }Set Environment Variables:
S3_BUCKET_NAME: Your S3 bucket name.
RESUME_KEY: The key (path) to your resume PDF file in S3.


Steps to Create Lambda Function for Visitor Counter:
Create a second Lambda function called
VisitorCounterFunctionusing the same steps as above.Lambda Code:
import json import boto3 from decimal import Decimal # Initialize DynamoDB resource dynamodb = boto3.resource('dynamodb') table = dynamodb.Table('visitorCounterTable') # Helper function to convert Decimal to int or float def decimal_default(obj): if isinstance(obj, Decimal): return int(obj) if obj % 1 == 0 else float(obj) raise TypeError def lambda_handler(event, context): try: # Define the primary key (static 'id' for counting visitors) visitor_id = "visitorCount" # Update the visitor count in DynamoDB response = table.update_item( Key={'id': visitor_id}, UpdateExpression="SET visits = if_not_exists(visits, :start) + :increment", ExpressionAttributeValues={ ':start': 0, ':increment': 1 }, ReturnValues="UPDATED_NEW" ) # Get the updated visitor count updated_visits = response['Attributes']['visits'] # Return response with CORS headers return { 'statusCode': 200, 'headers': { 'Access-Control-Allow-Origin': '*', # Allow any origin 'Access-Control-Allow-Methods': 'GET', # Allow GET method 'Access-Control-Allow-Headers': 'Content-Type', # Allow Content-Type header }, 'body': json.dumps({'visits': updated_visits}, default=decimal_default) } except Exception as e: print(f"Error updating visitor count: {str(e)}") return { 'statusCode': 500, 'headers': { 'Access-Control-Allow-Origin': '*', 'Access-Control-Allow-Methods': 'GET', 'Access-Control-Allow-Headers': 'Content-Type', }, 'body': json.dumps({'message': f'Error: {str(e)}'}) }

4.3 API Gateway Setup
Steps:
Create a new API in API Gateway.
Go to API Gateway in the AWS Console.
Create a REST API.
Name it
resumeDownload
Create Resource and Method for Resume Download:
Create a resource
/resume.Under
/resume, create a GET method.Integrate the method with the
ResumeDownloadFunctionLambda function.

Create Resource and Method for Visitor Counter:
Create a resource
/visitCount.Under
/visitCount, create a GET method.Integrate the method with the
VisitorCounterFunctionLambda function.
Enable CORS for both endpoints in API Gateway.
Deploy API:
Go to "Deploy API" in API Gateway.
Create a new stage (e.g.,
dev).Note down the endpoint URL for both
/resumeand/visitCount.
5. Resume Download Functionality
5.1 Implementation Overview
The resume is stored as a PDF in an S3 bucket.
The Lambda function fetches the resume from S3 and sends it to the user.
The API Gateway acts as the entry point, invoking the Lambda function.
5.2 S3 Configuration
Create an S3 Bucket:
Go to S3 in the AWS Console.
Create a bucket (e.g.,
resume-bucket).Upload your resume as a PDF file.
Ensure the file is accessible via the S3 read permissions set in the IAM role.
5.3 API Gateway-Lambda Integration
The
/resumeendpoint calls the Lambda function to fetch the resume.The Lambda function fetches the resume from S3 and encodes it in base64 format to be sent to the user via API Gateway.
6. Visitor Counter Functionality
6.1 Implementation Overview
A DynamoDB table stores the visitor count.
The Lambda function increments the count each time it is invoked and returns the updated count.
6.2 DynamoDB Configuration
Create a DynamoDB Table:
Go to DynamoDB in the AWS Console.
Create a table called
VisitorCounter.Set
idas the partition key.Prepopulate the table with an item:
jsonCopy code{ "id": "visitor_count", "visit_count": 0 }


API Deployed

6.3 API Gateway-Lambda Integration
- The
/visitCountendpoint calls the Lambda function, which increments and returns the updated visitor count.
Access web application through S3 static webapp


7. Security Measures
IAM Role: Ensure that the Lambda function has only the required permissions (S3 read, DynamoDB access).
API Gateway Authorization: Consider adding an API key or Cognito for access control.
S3 Bucket: Enable server-side encryption (SSE-S3 or SSE-KMS) for the resume file.
AWS WAF: Add a Web Application Firewall (WAF) to protect your API endpoints.
8. Budget Considerations
Lambda: AWS Lambda comes with 1M free requests and 400,000 GB-seconds of compute time, which should be sufficient for low-traffic websites.
S3: S3 provides 5GB of free storage and 20,000 GET requests/month within the Free Tier.
DynamoDB: DynamoDB offers 25 RCU/WCU (Read/Write Capacity Units) and 25GB of free storage per month.
API Gateway: The Free Tier includes 1M REST API calls per month.
By staying within these limits, the overall cost will remain under $10.
9. Deployment Diagram
10. Final Testing & Validation
Test API Endpoints:
Ensure the
/resumeendpoint returns the PDF correctly.Ensure the
/visitCountendpoint increments and returns the visitor count.
Frontend Integration:
Integrate the API URLs with the frontend (index.php).
Test the resume download and visitor counter.
Monitor Logs:
- Use CloudWatch to monitor Lambda executions and catch any potential errors.
This documentation provides a comprehensive guide to setting up a serverless web application using AWS services like Lambda, API Gateway, S3, and DynamoDB. Follow these steps closely to implement the resume download and visitor counter functionalities within a budget of $10.



